
Knowledge distillation refers to the process of transferring the knowledge from a large unwieldy model or set of models to a single smaller model that can be practically deployed under real-world constraints.The end goal is to develop accurate models that are more computationally efficient.
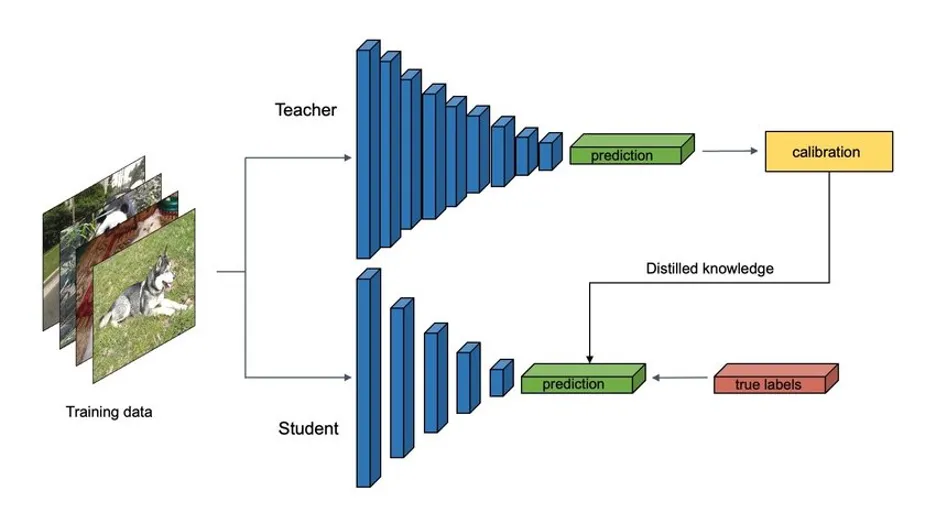
The process of knowledge distillation is more frequently used with neural network models that have complicated topologies with many layers and model parameters. Knowledge distillation approaches have therefore become more popular due to the development of deep learning over the past ten years and its effectiveness in a variety of domains, including speech recognition, image recognition, and natural language processing.
The challenge of deploying large deep neural network models is especially pertinent for edge devices with limited memory and computational capacity. To tackle this challenge, a model compression method was first proposed to transfer the knowledge from a large model into training a smaller model without any significant loss in performance. This process of learning a small model from a larger model was formalized as a “Knowledge Distillation”

As shown above Figure, In knowledge distillation, a small “student” model learns to mimic a large “teacher” model and leverage the knowledge of the teacher to obtain similar or higher accuracy.
There are several ways to distill the knowledge of the Teacher model into a simpler Student model. The main techniques are Self, Offline, and Online.

Self approaches benefit from more diverse data sources and, in some cases, less biased data. In the case of Offline, the Teacher is trained, and then the model is transferred directly to the Student. Online uses the ensemble result from multiple soft target Student models to generate a Student model.
- Offline distillation
Offline distillation is the most common method, where a pre-trained teacher model is used to guide the student model. In this scheme, the teacher model is first pre-trained on a training dataset, and then knowledge from the teacher model is distilled to train the student model. Given the recent advances in deep learning, a wide variety of pre-trained neural network models are openly available that can serve as the teacher depending on the use case. Offline distillation is an established technique in deep learning and easier to implement.
- Online distillation
In offline distillation, the pre-trained teacher model is usually a large capacity deep neural network. For several use cases, a pre-trained model may not be available for offline distillation. To address this limitation, online distillation can be used where both the teacher and student models are updated simultaneously in a single end-to-end training process. Online distillation can be operationalized using parallel computing thus making it a highly efficient method.
- Self-distillation
In self-distillation, the same model is used for the teacher and the student models. For instance, knowledge from deeper layers of a deep neural network can be used to train the shallow layers. It can be considered a special case of online distillation, and instantiated in several ways. Knowledge from earlier epochs of the teacher model can be transferred to its later epochs to train the student model.
Technique #1: Use DistilBERT instead of BERT
- DistilBERT has the same general architecture as BERT, but only half the layers of BERT.
- DistilBERT was trained on eight 16GB V100 GPUs for around 90 hours.
- KD is done during the pre-training phase, reducing the size of BERT by 40% while retaining 97% accuracy and becoming 60% faster.
Technique #2: Convert the model to ONNX
- Convert the DistilBERT model to ONNX format.
- It is effectively a serialized format to represent the model and additionally functions as a model compression technique
Technique #3: use a suitable AWS instance type
- Use inf1.6xlarge instance type to bring down latency further
- 24 vCPU, 48 GiB memory
- 4 AWS Inferentia chips — dedicated to inference with a large on-board memory cache and speeds of 128 TOPS
- Much better than g4dn.2xlarge(GPU) & c5–9xlarge(compute intensive) instance types
Conclusions
Modern deep learning applications are based on cumbersome neural networks with large capacity, memory footprint, and slow inference latency. Deploying such models to production is an enormous challenge. Knowledge distillation is an elegant mechanism to train a smaller, lighter, faster, and cheaper student model that is derived from a large, complex teacher model. There has been a massive increase in the adoption of knowledge distillation schemes for obtaining efficient and lightweight models for production use cases. Knowledge distillation is a complex technique based on different types of knowledge, training schemes, architectures and algorithms. Knowledge distillation has already enjoyed tremendous success in diverse domains including computer vision, natural language processing, speech amongst others.
For more details contact info@vafion.com
Follow us on Social media : Twitter | Facebook | Instagram | Linkedin
Similar Posts:
- No similar blogs
