
Microservices Architecture
This is one of the pattern languages used in the application development. A pattern language is a method of describing good design practices within a field of expertise.
The Scale Cube
This is the three dimension scalability model.
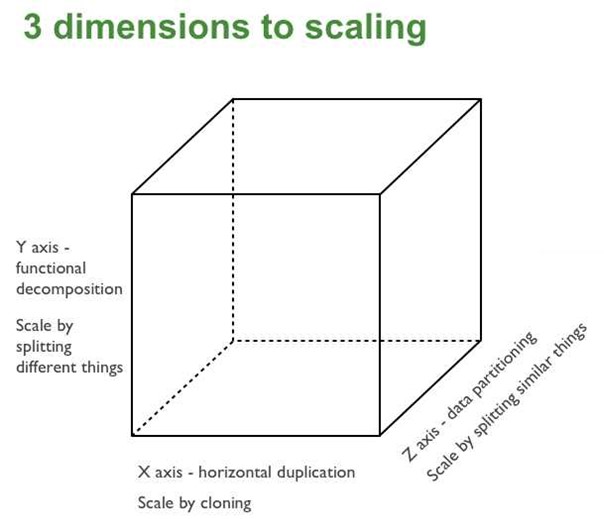
X-axis scaling
X-axis scaling consists of running multiple copies of an application behind a load balancer. If there are N copies then each copy handles 1/N of the load. This is a simple, commonly used approach of scaling an application. One drawback of this approach is that because each copy potentially accesses all of the data, caches require more memory to be effective. Another problem with this approach is that it does not tackle the problems of increasing development and application complexity.
Y-axis scaling
Unlike X-axis and Z-axis, which consist of running multiple, identical copies of the application, Y-axis axis scaling splits the application into multiple, different services. Each service is responsible for one or more closely related functions.
Z-axis scaling
When using Z-axis scaling each server runs an identical copy of the code. In this respect, it’s similar to X-axis scaling. The big difference is that each server is responsible for only a subset of the data. Some component of the system is responsible for routing each request to the appropriate server.
Microservices Architecture
When developing server-side enterprise application it should support a variety of different clients including desktop browsers, mobile browsers and native mobile applications. It might expose an API for 3rd parties as well to consume. It might also integrate with other applications via some techniques like web services. The application handles requests (HTTP requests and messages) by executing business logic; accessing a database; exchanging messages with other systems; and returning a HTML/JSON/XML response. The application has different types of components viz.,
- Presentation logic
- Business logic
- Database access logic
- Application integration logic
Architect the application by applying the Scale Cube (specifically y-axis scaling) and functionally decompose the application into a set of collaborating services. Each service implements a set of narrowly, related functions. Services communicate using either synchronous protocols such as HTTP/REST or asynchronous protocols such as AMQP. Services are developed and deployed independently of one another. Each service has its own database in order to be decoupled from other services. When necessary, consistency is between databases is maintained using either database replication mechanisms or application-level events.
Example
Let’s imagine that we are building an e-commerce application that takes orders from customers, verifies inventory and available credit, and ships them. The application consists of several components including the StoreFront UI, which implements the user interface, along with some backend services for checking credit, maintaining inventory and shipping orders. The application is deployed as a set of services.

Benefits
Each microservice is relatively small
Easier for a developer to understand
The web container starts faster, which makes developers more productive, and speeds up deployments
Each service can be deployed independently of other services – easier to deploy new versions of services frequently
Improved fault isolation. For example, if there is a memory leak in one service then only that service will be affected. The other services will continue to handle requests
Each service can be developed and deployed independently
DrawBacks
Testing is more difficult
Developers must implement the inter-service communication mechanism.
Implementing use cases that span multiple services without using distributed transactions is difficult
Increased memory consumption. The microservices architecture replaces N monolithic application instances with NxM services instances. If each service runs in its own JVM (or equivalent), which is usually necessary to isolate the instances, then there is the overhead of M times as many JVM runtimes.
Similar Posts:
- No similar blogs
