
Ask anyone in the data industry what’s hot these days and “data mesh” will be at the top of the list. But what is a data mesh and why should you build one?
Global data creation is projected to exceed 180 zettabytes in the next five years. Current data platforms have several architectural failures that hinder enterprise data processing and inhibit business growth.
What is Data Mesh?
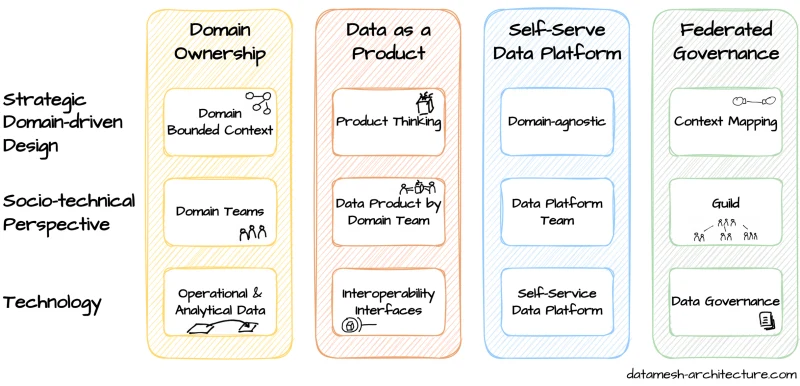
Data mesh is a new method based on a modern, distributed architecture for analytical data management. It is a decentralised organisational and technical approach to sharing, accessing, and managing data for analytics and ML.
It enables end-users to easily access and query data where it lives without first transporting it to a data lake or data warehouse.
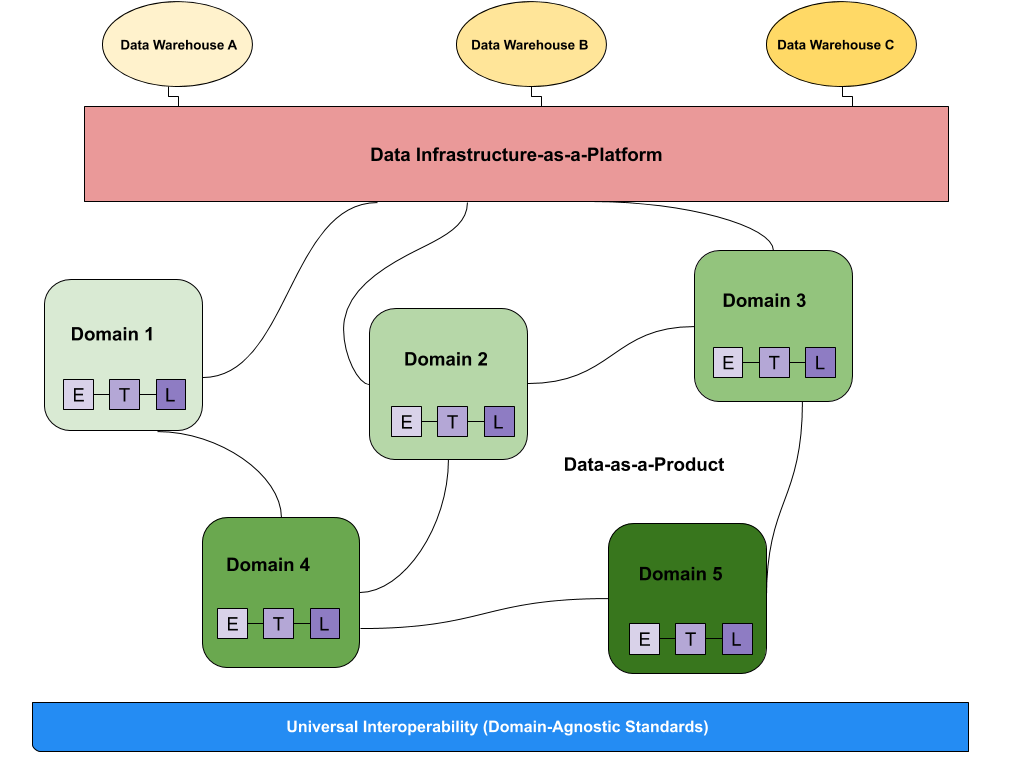
The decentralized strategy of data mesh distributes data ownership to domain-specific teams that manage, own, and serve the data as a product
The principal goal of data mesh is to take away the demanding situations of data availability and accessibility at scale. Data mesh lets business users and data scientists alike access, analyze, and operationalize commercial enterprise insights from virtually any data source, in any location, without intervention from professional data teams.
Simply put, data mesh makes data accessible, available, discoverable, secure, and interoperable. The quicker access to query data directly translates into quicker time to value without needing data transportation.
Why use a Data Mesh ?
Data mesh provides a solution to the drawbacks of data lakes by allowing greater autonomy and flexibility for the data owners, facilitating greater data experimentation and innovation while reducing the burden on data teams to field the needs of every data consumer through a single pipeline.
Meanwhile, the data meshes’ self-serve infrastructure-as-a-platform provides data teams with a universal, domain-agnostic, and often automated approach to data standardization, data product lineage, data product monitoring, alerting, logging, data collection and sharing. These benefits provide a competitive edge compared to traditional data architectures, which are often hamstrung by the lack of data standardization between both investors and consumers.
Data Mesh or Data lake?
Comparing data mesh to data lake is very futile as the terms are conceptually very different from each other. Data lakes are data storage repositories, which store, organize, protect and offer data while data mesh is a set of principles for decentralized data management. The main objective of both is to offer faster time to analytical insights and increase the business value of analytics.
How Does Data Mesh Empower Users?
Data mesh offers automated, comprehensive, instant analytics at scale. Data scientists – and data consumers with less expertise and training – will now be able to access their own business data, to conduct their own analysis focused on their own business needs.
This is a purely self-service strategy, with its single point of access control, represents for the first time a people-centric plan for data management. It will be a faster and more effective way to get answers without taxing the DevOps team, hoping for their availability. This is a major benefit for data teams.
Major Problems we faced in Current Data Platforms
- Until now, enterprises used a centralization strategy to process extensive data with various data sources, types, and use cases. However, centralization requires users to import/transport data from edge locations to a central data lake to be queried for analytics, which is time-consuming and expensive
To solve this the distributed architecture of data mesh views data as a product with separate domain ownership for the each and every single business unit. This decentralized data ownership model reduces the time-to-insights and time-to-value by empowering business units and operational teams to access and analyze data quickly and easily.
- As the global data volumes increase, the query method in a centralized management model needs to change in the entire data pipeline that fails to respond at scale. It slows down the response time to newly consumers/data sources as the number of sources increases, which negatively affects business agility to get value from data and respond to change.
Data mesh delegates datasets ownership from the central to the domains (individual teams or business users) to enable business agility and change at scale. Data mesh architecture steers enterprises towards real-time decision-making by closing the time and space gap between an event happening and its consumption/process for analysis.
The current enterprise data platform architecture is centralized, monolithic, and domain agnostic (data lake). The software engineering teams transitioned from monolithic applications to micro service architectures, the data mesh is, in many ways, the data platform version of micro services. A data mesh is a type of data platform architecture that embraces the ubiquity of data in the enterprise by leveraging a domain-oriented, self-serve design.
Some of the transformational benefits that data mesh offers enterprises:
Faster Access and Accurate Data Delivery
Data mesh offers easily governable and centralized infrastructure based on a self-service model without underlying complexity for faster data access and accurate delivery. Businesses can access data from anywhere with SQL queries with much lower latency. The distributed architecture reduces the processing and intervention layers that delay time to insight.
Flexibility and Independence
Enterprises adopting data mesh architecture are becoming vendor-agnostic businesses that are not locked in with one data platform. The distributed infrastructure allows companies unparalleled flexibility and choices due to connectors to many systems.
Supporting AI and machine learning initiatives
The Data Mesh becomes an enabler of AI and ML innovation, with teams even having the freedom to create data products specifically for AI and ML use — making the capabilities accessible to more teams and across more domains than ever before.
Creating truly data-driven cultures of innovation
The biggest advantages of a decentralized architecture like Data Mesh is that it will put the end users of data in control of how it’s managed and used.In a Data Mesh, domain teams are in the driver’s seat. As the custodians and controllers of their own data products, they’re free to experiment with that data however they like. They can ask more questions, simulate more scenarios, and explore more data-driven ideas — the kinds of things that lead to lasting, meaningful innovations.
Image Reference :-
For more details contact info@vafion.com
Similar Posts:
- No similar blogs
