
Apache Pinot is a real-time distributed OLAP( Online Analytical Processing) data store that is the technology behind much business intelligence. Apace pinot is mainly built to provide ultra-low latency analytics even at high throughput.

Pinot was developed by the engineers at Linkedin and Uber. This was designed to power-rich interactive real-time applications to find information such as Who Viewed your Profile, Talent Insights, Company Analytics, and more. In LinkedIn, Pinot supports 50+user facing products and serves 100k+ queries per second.
FEATURES OF APACHE PINOT
Column-oriented
Apache Pinot is a Column-oriented database that includes many compression schemes such as Fixed Bit Length and Run Length.
Query Optimization
Pinot has the ability to optimize the query and also can execute plans based on the query and segment metadata.
Query with SQL
It works on languages like SQL that supports selection, Aggregation, filtering, group by, and distinct queries on data.
Multivalued Fields
Pinot supports Multi valued fields, it allows to read query fields as comma-separated values.
ORIGIN OF APACHE PINOT
Pinot first started Apache incubation in 2018, for a few years pinots had been set as open-source and from here pinot gained traction, over time the growth of pinot improves steadily as more and more companies found value in its capabilities to give fast analytics for a variety of use cases. At the same time, Pinot is also used by other companies like Microsoft, Factual, and Weibo to power both external and internal analytics use cases.
AREAS OF IMPROVEMENT
Working closely with Pinot engineers found there are some areas to be improved to get accurate output.
Restrictive pluggability
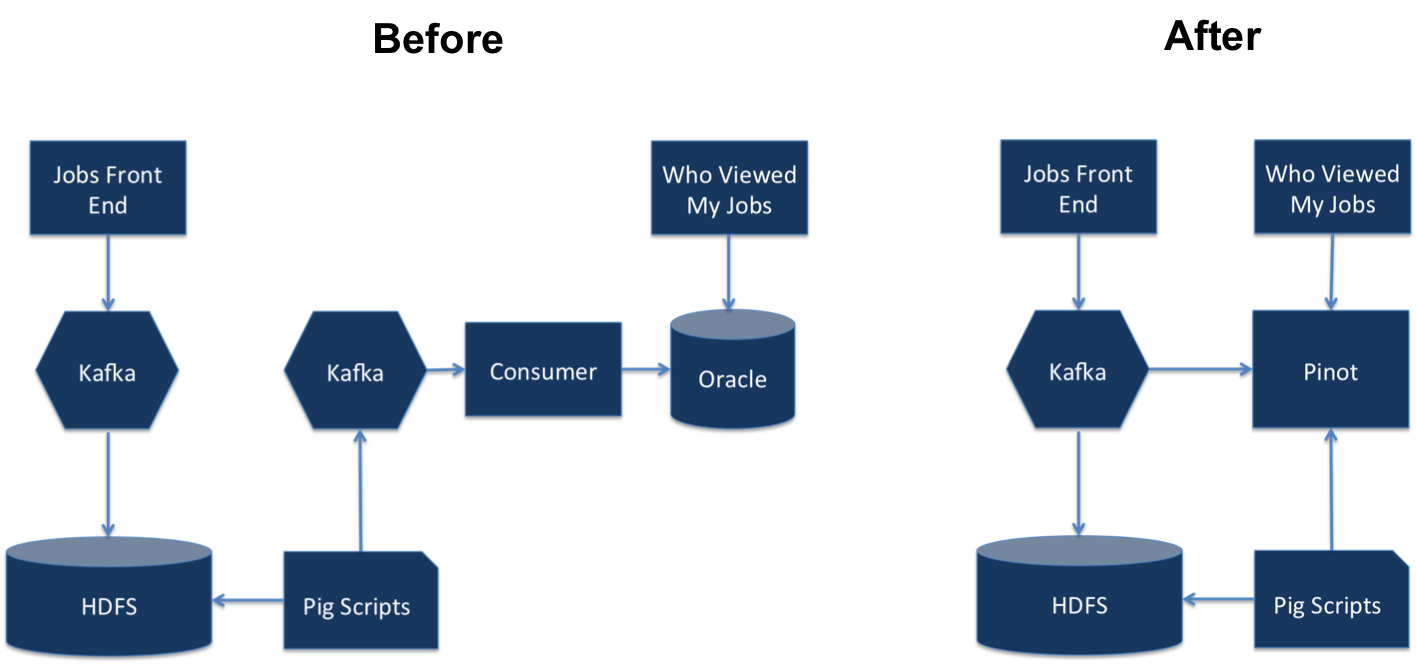
Big data Analytics concludes that 0.1.x of Pinot ways to plug-in streams other than Kafka, but its implementation was still closely tied to Hadoop and Avro. Due to this compile-time dependency on these technologies, it makes it hard to integrate with other systems.
Absence of Cloud- Native support
Some of the toolings around Pinot were not built to embrace cloud-native technologies. These include Containers, Docker, Kubernetes, etc, which makes it harder for the community to operate Pinot on Cloud.
Decentralized Documentation
The most common piece of feedback that received from users is Better documentation. Pinot has only ample documentation and it was not as friendly to users who wanted to try pinot out. It was only developed to power internal data analytics products. Various complex operations such as adding nodes or rebalancing a workload can be performed without any downtime. The main issue is that users did not know about the right way to operate Pinot at scale and often ran into the lack of documentation for these operations.
NEW APACHE PINOT 0.3.0
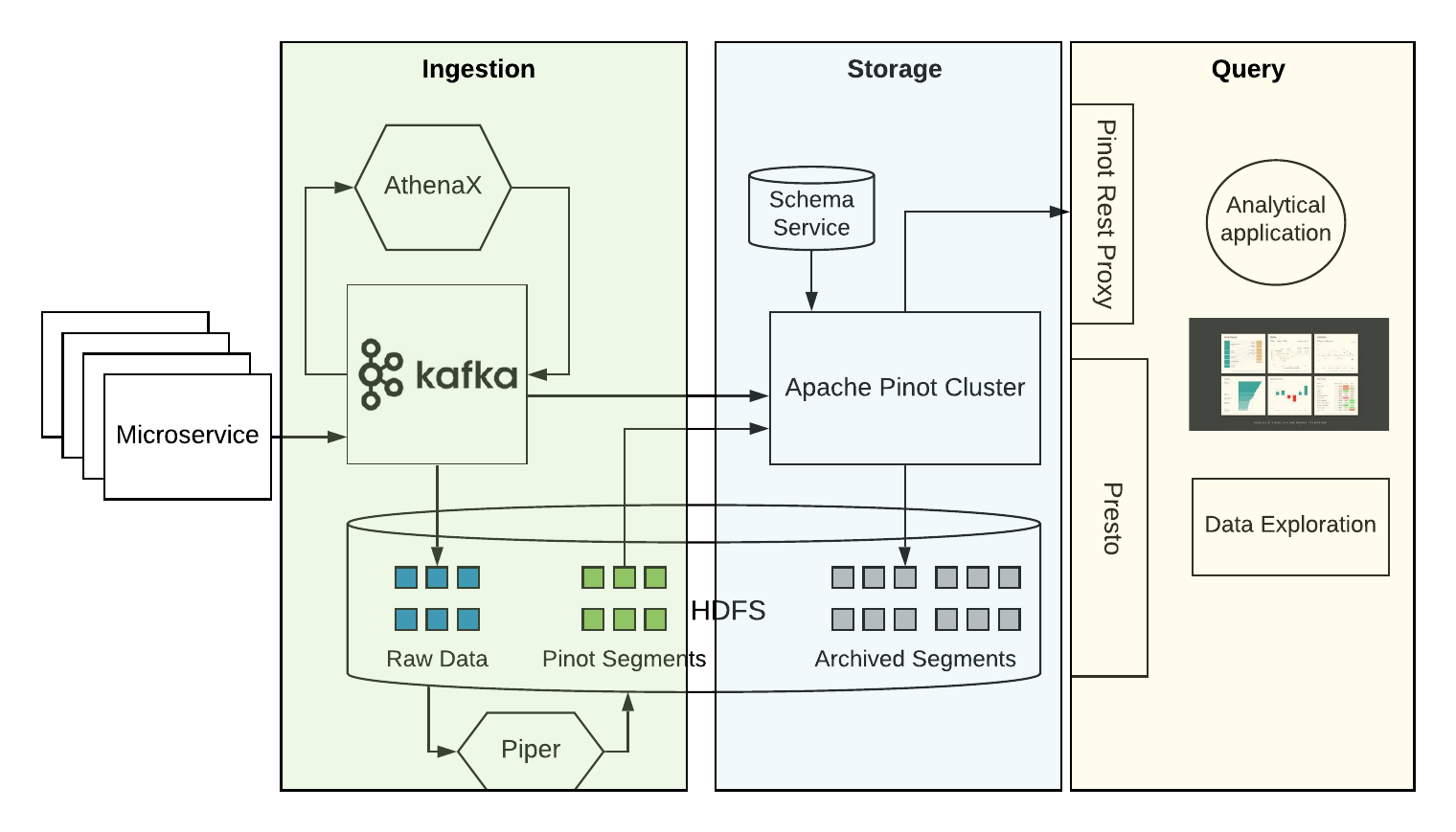
To overcome the above issues a new version of Apache Pinot 0.3.0 was introduced. Now, this is the time to tackle the improvements one by one to move forward and find a better Pinot for the community.
Full SQL Support on Pinot
They introduced two things to make Pinot’s query language richer and accessible.
PQL To SQL
In this technique, the custom PQL is moved to calcite SQL. Apache calcite is the most popular open-source framework used for building database and data management systems. SQL parser, an API for building expressions in relational algebra, and query planning engine are included in Apache Calcite. It focuses on providing fast analytics
on a single table and it is considered as the design choice in Pinot.
Presto To Pinot Connector
With this technology, users get full SQL functionality, and it was built by the Analytics infra team at UberEats for users to perform joins on data on Pinot. The Pinot Connectors have many optimizations to get the best of Presto and Pinot and also built with some additional features like predicate push-down and aggregation/group by push down. This presto to pinot connector helps to achieve fast analytics on single tablets and deliver richer analytics for nested queries.
Enabling Cloud-Based Support
This Method Allows Cloud-based support for Apache pinot. Here the system has collaborated with the open-source community to add support for Kubernetes and helps system administrators to deploy Pinot across various cloud providers.
Expanded Documentation
This new version provides large documentation for the users and this time a new set of documentation and videos are created to target the first-time users for a smoother experience.
Conclusion
The development of Apache Pinot version 0.3.0 allows the ability to run Pinot on any cloud because it is built with full SQL support through Presto to Pinot Connector. The next version of the infrastructure on Azure will be focused on broader support for the cloud which is also useful for the internal use of Pinot.
Image credits: xyzf.com
Similar Posts:
- No similar blogs
